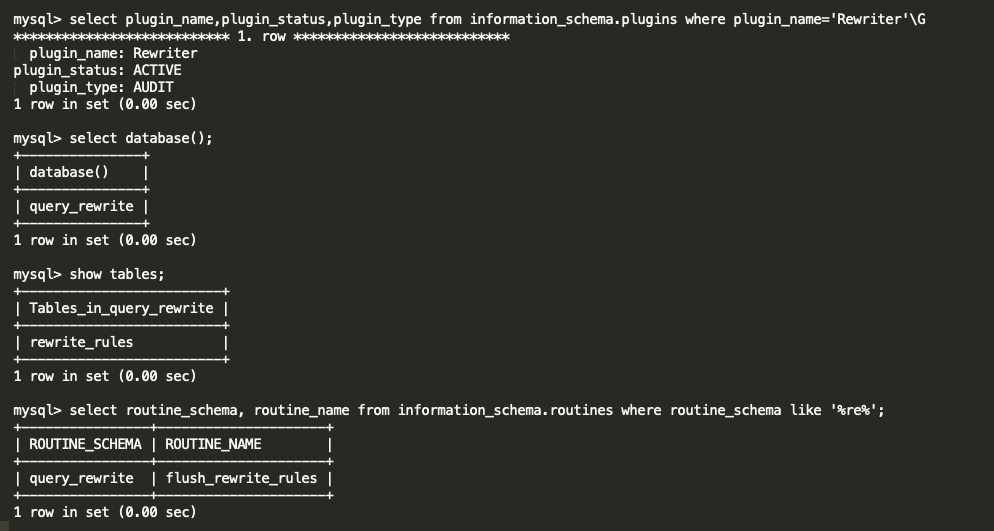
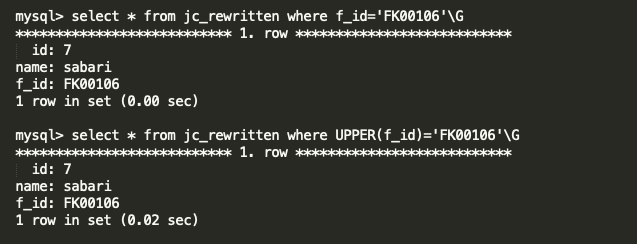
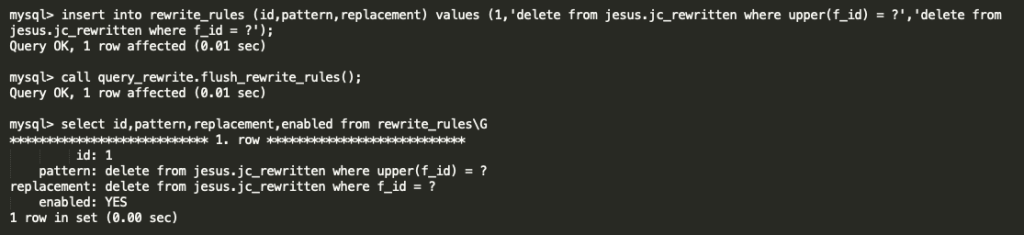
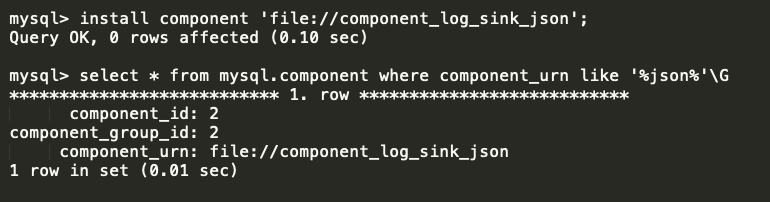
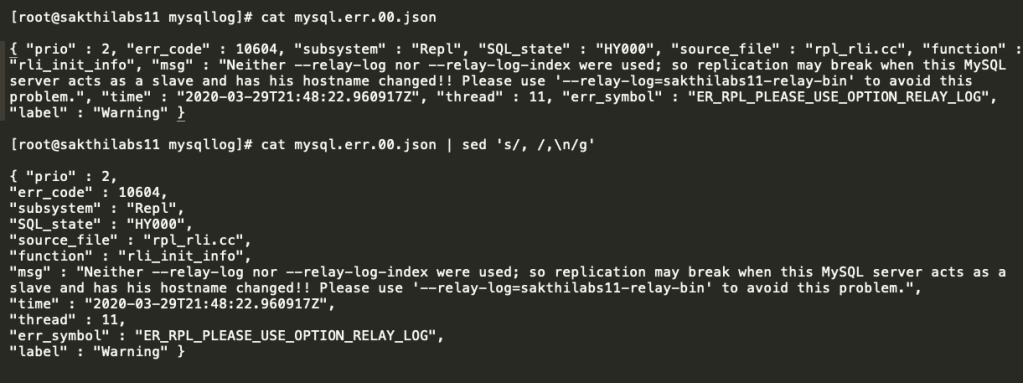
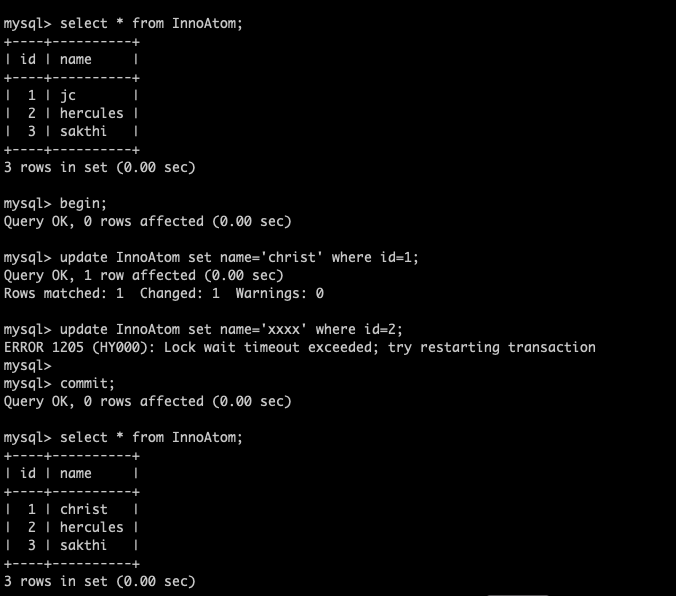
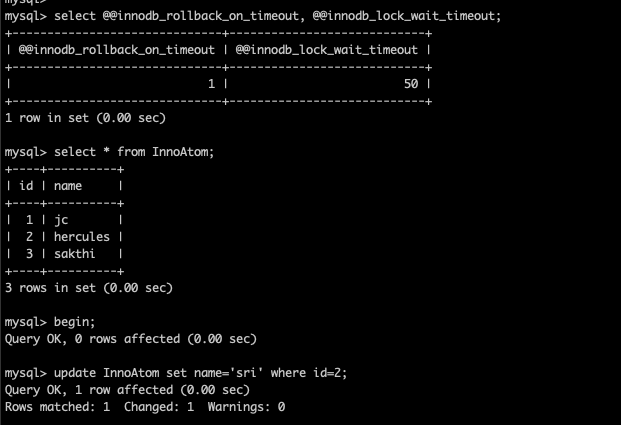
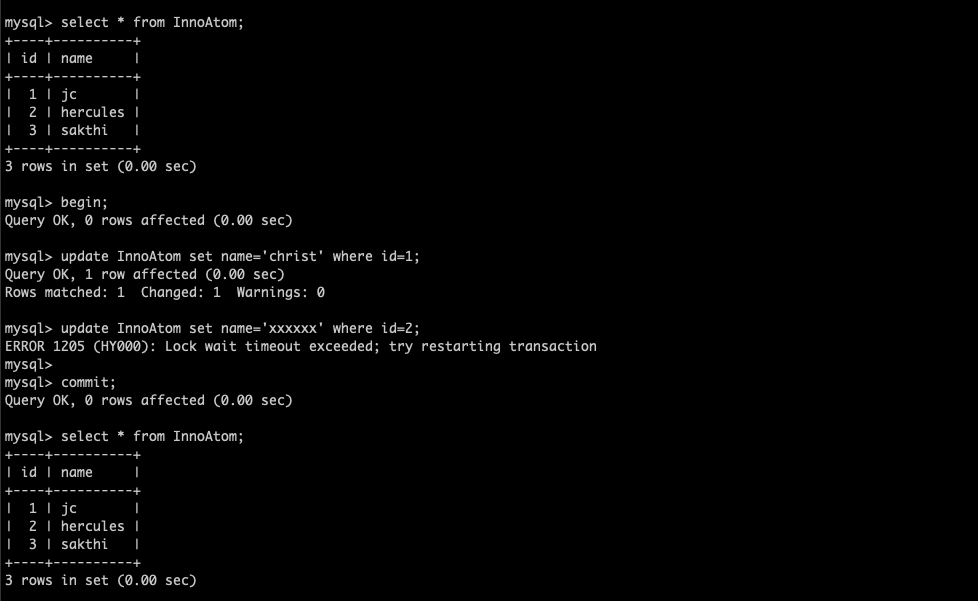
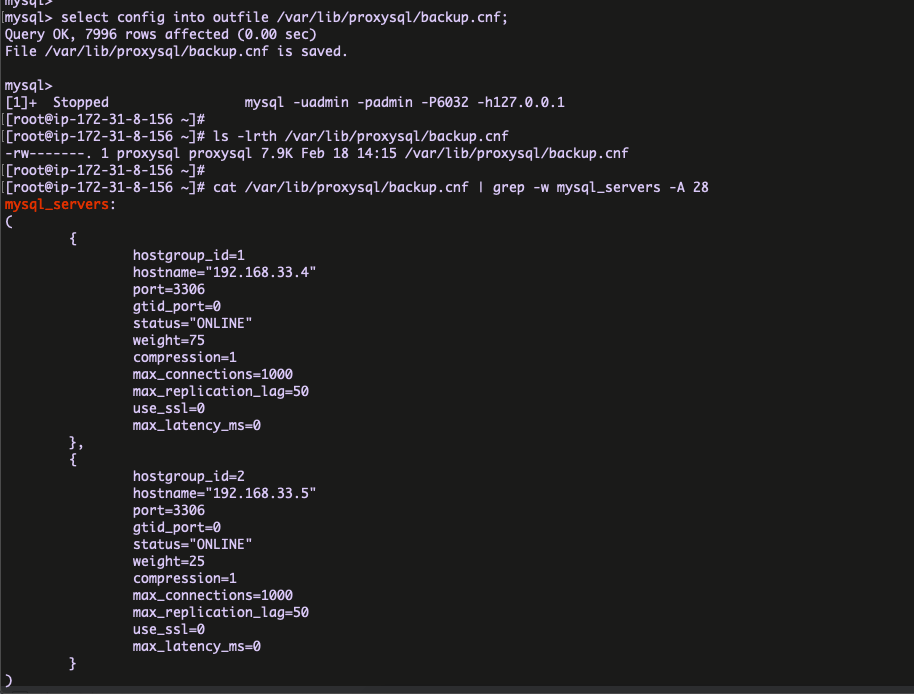
In this blog, I am going to share the MySQL 8 InnoDB architecture diagram with related variables . From the MySQL official document I have seen some InnoDB variables related to MySQL 8.0.20 . The architecture has been prepared based on that . Also, I am providing the variables list which used in this diagram and its respective versions .
MySQL 8 InnoDB Architecture :

- For understand the diagram better , I have added some old variables as well ( sync_binlog / innodb_log_buffer / innodb_flush_log_at_trx_commit / innodb_flush_method etc .. )
- I have marked the MySQL 8 variables with yellow colour .
MySQL 8 variables :
- innodb_buffer_pool_in_core_file ( 8.0.14 )
- innodb_doublewrite_batch_size (8.0.20)
- innodb_doublewrite_dir (8.0.20)
- innodb_doublewrite_files (8.0.20)
- innodb_doublewrite_pages (8.0.20)
- innodb_fsync_threshold (8.0.13)
- innodb_idle_flush_pct (8.0.18)
- innodb_log_checkpoint_fuzzy_now (8.0.13)
- innodb_parallel_read_threads (8.0.14)
- innodb_redo_log_archive_dirs (8.0.17)
- innodb_spin_wait_pause_multiplier (8.0.16)
- innodb_temp_tablespaces_dir (8.0.13)
Conclusion :
Few months back, I have released the MySQL 8 architecture diagram . But, the image quality is very low . So, some peoples personally asked me to send the original image through email . But, unfortunately I don’t have that. So, I had the plan long time to draw the diagram again and release it in my website. It Happens now 🙂 . Also, the current diagram have some modifications as well . Thanks to everyone , who encouraging me to draw this diagram again . I will be come up with my next blog as much as possible .
Thanks !!!
Promotion:
If you are looking any MySQL related training or support, you can reach me on following details.
email: hercules7sakthi@gmail.com
LinkdIN: https://www.linkedin.com/in/sri-sakthivel-m-d-68abb8112/